In how many moves can you go from 'ANANAS' (part of the scientific name of the pineapple) to 'BANANA'? And how many words can you reach in 3 moves? No, this article is not about the similarities of the fruits (although they are both yellow and sweet), nor about moving between their locations in a supermarket (for that, you could check out this article!). This article is about modifying words. In particular, we will talk about changing one word into another via 'moves'.
What is a move? We get to choose that! A simple example of a move is a substitution. This simply means changing one letter in the word to another. Like this, you can go from 'ROW' to 'RAW' in exactly one move. But to go from 'ANANAS' to 'BANANA' you need 6 moves, because you need to change all the letters.
The smallest number of substitutions needed to go from one word to another is called the Hamming distance. It is easy to compute: you first check whether the first letters match, then whether the second letters match, et cetera. In the end, you simply count the number of letters that were different.
What if you could choose other kinds of moves? Are there moves that would allow you to go from 'ANANAS' to 'BANANA' faster?
What is the distance between 'ANANAS' and 'BANANA', if you are allowed to remove a letter or add a letter in a move?
If you remove the 'S' at the back of 'ANANAS', and add a 'B' in front, you get the desired result. If we consider the addition or removal of a letter (anywhere in the word) as a move, we can go from one word to another much faster. In other words, we need fewer moves. The number of moves needed with these kinds of moves is called the Levenshtein distance. In literature, Levenshtein distance is often referred to as "edit distance". The moves are referred to as "edits". It is a much more realistic way to measure the similarity of words. The problem: it is not easy to compute this distance!
The Levenshtein distance between 'ANANAS' and 'BANANA' is 2!
Why is this BANANAS problem actually interesting from a practical point of view? For instance, when writing a text, we are prone to making small mistakes (typos). These change the word slightly, leading to incorrect versions of a word, or even to different words that actually make sense. Suppose you want to search for a word in a text. In most text editors, you can access the search feature via the CTRL+F command. If you were to search for a word this way, you may not find all occurrences of that word. This is because it only finds exact matches, not the words with a typo!
The search function can be generalized to find occurrences with a few errors as well. Say you want to find all ocurrences [sic] of the word "occurrence" in the text. Since this word is not trivial, some typo can always appear. Still, you do not want to miss any occurence [sic]. How do you make sure the search function returns the relevant words, but not every single word of the text? You could make the search function return words that are a small distance away from your search query!
Using Hamming distance for search is not the best idea. Suppose your groupmates wrote "acommodates" somewhere in your group project. Ideally, you want to search the correct spelling of the base word "accommodate" and find all the errors. However, the Hamming distance between "acommodates" and "accommodate" is 7! For comparison, the word "incorporate" is 5 moves away and "reformulate" is 6 moves away.
Note how we are comparing one version with an 's' and one version without an 's'? Ideally, when you search "accommodate", you want to find words like "accomodate", "acommodates", "acomodates". The first two words are one letter shorter than your search word, and last word is two letters shorter! How should the Hamming distance be computed if the word lengths don't match? It is unclear, and this is another issue of Hamming distance.
A better idea is to use the edit distance (Levenshtein distance). I invite you to consider the correct spelling "accommodate" and compute the distance to the following words:
As you may have noticed, calculating the edit distance can be a bit of a puzzle. For "acclimate" for instance, the distance of four is obtained through 2 deletions and 2 substitutions (which ones?). As a result, the algorithm to calculate this distance for any two words is more difficult. The time it takes to calculate it is proportional to the length of the first word, multiplied by the length of the second word. It is believed there exists no faster way.
The problem is not solvable in strongly subquadratic time unless SETH (Strong Exponential Time Hypothesis) is false. That is, such a result would be groundbreaking for the whole of algorithmics. The simplest quadratic (running in time proportional to the product of lengths of both words) algorithm requires computing the distance over all pairs of prefixes of both words X and Y - which can be simply done with the formula :
,
,
,
,
where and iterate over all the positions in words and , and denotes the letter at position in word . The four possible values to choose from correspond to using identity (do nothing), substitution, insertion and deletion respectively to match the last letters of the prefixes. There exist faster algorithms for special cases of the problem, for example parameterized by the distance, that is working faster if the distance between the words is actually quite small (for example instead of , where are the lengths of the words and is their distance).
Let's move on to the next question: how many words can we reach in just a few moves? Why could this be useful? Perhaps you want to know how many words are expected to be found with the generalized search function, before generating them. More notably, it turns out to be useful when looking for DNA sequences inside a database.
Before diving into a solution, we have to make a few more preparations. Denote by the distance in which we are interested: we want to count the size of a -neighborhood, that is the number of distinct words at a distance at most . We denote the length of the word by . Finally, we need to describe the alphabet, which is the collection of letters that the words can use. In Latin/English, there are 26 letters in the alphabet, but this is not always the case in other languages. Computers may use an alphabet of 0 and 1's, or all ASCII signs, for instance. In the case of DNA, the alphabet is usually (four nucleobases). We will use a standard notation of for the alphabet and for its size.
What happens if is unbounded (you can think of it as )? What if is unbounded? And if is unbounded?
If any of these values is unbounded, we get an infinite number of words in the -neighborhood.
Let . Can you find all the words at distance 1 from word 'AA' and all the words at distance 1 from word 'AB'? First do this for the Hamming distance, then for edit distance.
Hamming distance with the substitutions marked in blue:
Edit distance, with moves marked. A letter in green marks an insertion, a red line marks a deletion.
Once again Hamming distance turned out much less difficult. This is partly because there is only one possible kind of move. But there is another factor: with the edit distance, the same word can be obtained in different ways. With Hamming distance, every combination of moves (substitutions) results in a unique word.
Can you derive a formula for the number of words at Hamming distance at most from a word?
Hint: you have to sum over all possible distances, from distance (the word itself) up to and including distance . So your formula should look like (the sum of components with ranging from to ). You also need to use (the length of the word) and (the size of the alphabet).
The formula is\begin{equation} \sum_{i=0}^k \binom{n}{i}(\sigma - 1)^i. \end{equation}
Here, \begin{equation} \binom{n}{i} = \frac{n!}{i!(n-i)!}, \end{equation}
which is the binomial coefficient.
The reason behind this formula is simple: to perform substitutions we choose positions out of (the number of such choices is ), and for each of them choose independently one of the letters different from the original one.
The value of the formula itself can be computed in time proportional to , which is faster than even just reading the given word.
We can see that for Hamming distance, the number of neighbors does not depend on the word in question (just its length), while for edit distance, it does: 8 neighbors for 'AA' and 9 for 'AB'! This turns out to be why counting the number of neighbors is hard for edit distance.
We do not know an efficient way of counting those close words for any given word. This does not mean that this is difficult for every word. Let us look at 'An'= 'AAAA', the word where all letters are identical. Let us try to derive the size of the neighborhood of this particular together.
The first trick will be to condition over the number of letters different from 'A' in the final word. That is, let be the fixed number of letters different from 'A' in the final word. First question: what values can take?
It is between (no new letters introduced) and (it is impossible to introduce more than new letters).
Now we want to count the number of possible words we can make, given that we know . This is not so obvious. So we condition again! This time on the number of letters in the final word, which we denote . Next question: given that are different from 'A', what are the possible values of ?
The final word can have at most letters, because the 'best we can do' is to add letters. This would result in a word of length . The maximum length is therefore unrelated to .
If letters are different from 'A', this means that we must have done moves that are either a substitution or an insertion, because that is the only way to introduce new letters. This leaves at most deletions. Therefore, the final word is at least letters long.
Now the final counting challenge: given and , how many distinct final words (starting from 'An') exist? Hint: it resembles (a part of) the Hamming distance formula! Think about a final word, rather than the starting word.
The final word has letters, of which are different from 'A'. So we need to count the number of ways to choose positions out of . In each position one of letters (different from 'A') can be put. This gives a total of possible final words, given and .
The formula for this particular word is therefore \begin{equation} \sum_{i=0}^k \sum_{j=i-k}^k \binom{n+j}{i}(\sigma - 1)^i. \end{equation}
Okay, now we have a word for which computing the size of the -neighborhood is fast, but why is it meaningful? The answer comes in the form of a scientific paper (written by, among others, the author of this post), where it is shown that for any word of length , the number of neighbors is at least as large as for 'An'!
This was a brief introduction to word distances, in particular Hamming distance and Levenshtein distance. The latter is more sophisticated and realistic, it takes only two moves to go from 'ANANAS' to 'BANANA', but it comes at a cost: computing distances and -neighborhoods is far from straightforward. So, how similar are a pineapple and a banana? Just two moves apart, but whether that makes them similar is a matter of taste.
During our teenage years, everything changes. It’s no surprise that our brain does too. But how do we make sense of this transformation? Is there a way to quantify it? Networks might just be the answer.
One of the main building blocks of modern AI-tools are artificial neural networks, abstract models inspired by the structure and functions of biological neural networks which enable machines to "learn". In this article, I will discuss some thoughts on this topic.
Rafael Prieto-Curiel is a mathematician and a faculty member at the Complexity Science Hub in Vienna, Austria. His research focuses on crime, mobility, migration and urban dynamics. We interviewed Rafael to learn about his story.
We want our guts to be filled with a diverse range of mutually beneficial and competitive interactions, a perfect blend of friends, frenemies, and enemies to keep our guts active and body on its toes. Read how networks can help understand these interactions!



![T[i][j] = \text{min}](https://www.networkpages.nl/wp-content/plugins/latex/cache/tex_407ec8e6531a7f276bccc68670f2858b.gif)
![T[i-1][j-1] \text{ if } X[i] = Y[j]](https://www.networkpages.nl/wp-content/plugins/latex/cache/tex_3c4edee11b18af3d0e26c29419610ec2.gif)
![T[i-1][j-1] + 1 \text{ if } X[i] \neq Y[j]](https://www.networkpages.nl/wp-content/plugins/latex/cache/tex_7131f99e41aadd8e67757695b5c89317.gif)
![T[i-1][j] + 1](https://www.networkpages.nl/wp-content/plugins/latex/cache/tex_bf2302701c8a1709d394fb2846e6e927.gif)
![T[i][j-1] + 1](https://www.networkpages.nl/wp-content/plugins/latex/cache/tex_92a42f12511e5e7f7c383e935b5e81d1.gif)
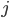
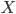

![X[i]](https://www.networkpages.nl/wp-content/plugins/latex/cache/tex_65746d19c9d0244f2d991fc55895f871.gif)



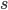
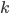 the distance in which we are interested: we want to count the size of a
the distance in which we are interested: we want to count the size of a 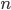 . Finally, we need to describe the alphabet, which is the collection of letters that the words can use. In Latin/English, there are 26 letters in the alphabet, but this is not always the case in other languages. Computers may use an alphabet of 0 and 1's, or all ASCII signs, for instance. In the case of DNA, the alphabet is usually
. Finally, we need to describe the alphabet, which is the collection of letters that the words can use. In Latin/English, there are 26 letters in the alphabet, but this is not always the case in other languages. Computers may use an alphabet of 0 and 1's, or all ASCII signs, for instance. In the case of DNA, the alphabet is usually  (four nucleobases). We will use a standard notation of
(four nucleobases). We will use a standard notation of  for the alphabet and
for the alphabet and 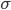 for its size.
for its size. )? What if
)? What if  . Can you find all the words at distance 1 from word 'AA' and all the words at distance 1 from word 'AB'? First do this for the Hamming distance, then for edit distance.
. Can you find all the words at distance 1 from word 'AA' and all the words at distance 1 from word 'AB'? First do this for the Hamming distance, then for edit distance.



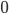 (the word itself) up to and including distance
(the word itself) up to and including distance  (the sum of components with
(the sum of components with 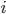 ranging from
ranging from 

 A', the word where all letters are identical. Let us try to derive the size of the neighborhood of this particular together.
A', the word where all letters are identical. Let us try to derive the size of the neighborhood of this particular together. . Next question: given that
. Next question: given that