A lot of services that we enjoy every day, for example commuting by train or ordering some product from a web-shop, give rise to very complex problems, like making the daily train schedule or deciding how all the products that have been ordered should be delivered. We ourselves are confronted with similar problems quite often, for example when we want to find a fast route to go somewhere. How can we efficiently solve such problems? In this article I will explain how a method called preprocessing works.
Imagine a large delivery company, that delivers the packages ordered online to everywhere in the Netherlands. Clearly, the company needs to decide which driver delivers which packages and in which order. The company, of course, wants to do this as quickly as possible to keep their customers satisfied. At the same time, they want to minimize their costs: they want the drivers to drive as few kilometers as possible, and use as few vehicles as possible. And of course, there are many other constraints as well, drivers want to work certain hours on certain days, cars need to be refueled on time, etcetera.
But how to schedule these package deliveries on a daily basis? In the past this had to be done manually, nowadays this is often done by algorithms. It appears however that this problem is inherently difficult to solve. Even with a single driver, and only ten packages to be delivered on a single day, there are more than three million possible schedules to deliver them to the customers. With more packages, this number quickly grows unimaginably large. So, trying all possibilities is infeasible. Maybe if we do some smart tricks we can reduce the number of possibilities we need to check. This is indeed possible, but as far as we know, going through lots and lots of possibilities is unavoidable, and this may take a very long time. This is problematic, since the delivery company needs to know which packages to give to which driver as soon as the morning begins. They cannot spend multiple days deciding on what to do next. This can mean that the best-possible schedule cannot be found in time, leading to drivers driving detours and using more fuel than necessary, or late deliveries, which we have probably all experienced.
Making the problem easier
Imagine you have to solve this problem for the delivery company. A first step to try could be to start by simplifying the problem, and getting rid of possible schedules that are clearly bad. We will call this first step a preprocessing step. For example, you could start by grouping the packages based on their destination. In this way, you can have some delivery drivers deliver all packages that go to Eindhoven, while others drive around Utrecht, and so on. In this way, you attempt to reduce the number of options you need to consider. In practice, of course, more complex rules can be used.
This type of preprocessing the problem is widely used in practice by algorithms that solve such scheduling problems. It can be very effective in some cases, and greatly reduce the time needed to find a good solution. In my research I study preprocessing that will have a guaranteed effect in simplifying the problem.
Puzzle
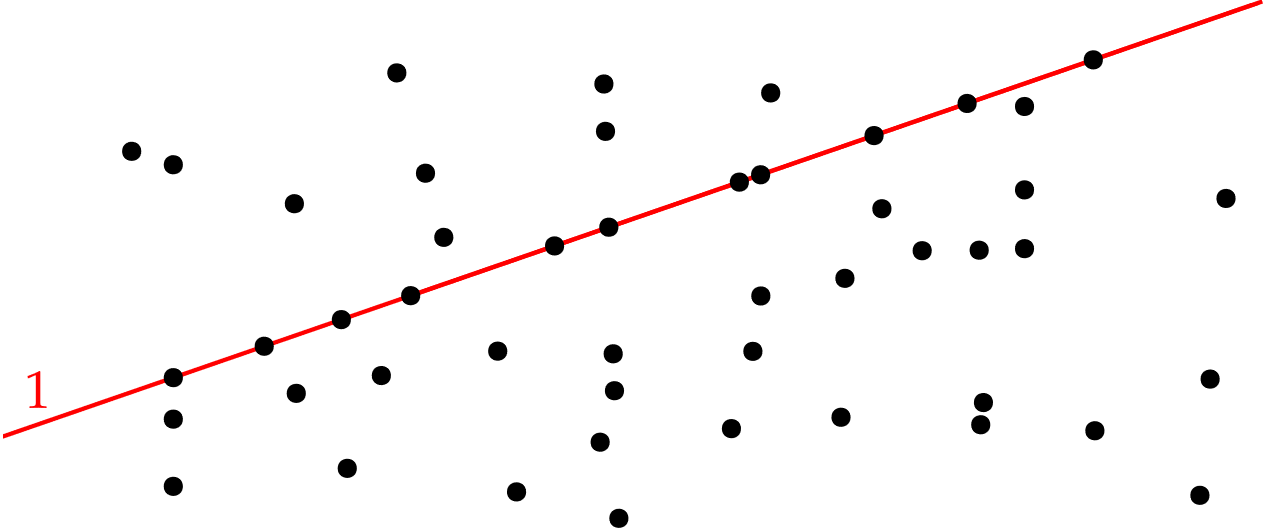
Let’s move away from the problem of delivering packages and look at a puzzle to understand how preprocessing works. It will illustrate that preprocessing can really make a problem simpler in some measurable sense, by repeatedly applying some rule to simplify it. We will consider a puzzle. Below, you see 48 points.
The challenge is to cover these points by drawing at most eight straight lines. You can use lines that are as long as you like, but they must be straight. For a point to be covered, a line has to go straight through its center.
The puzzle above has 48 points. With that many points to cover, how can you start solving the puzzle? Have a look at the red line drawn below.
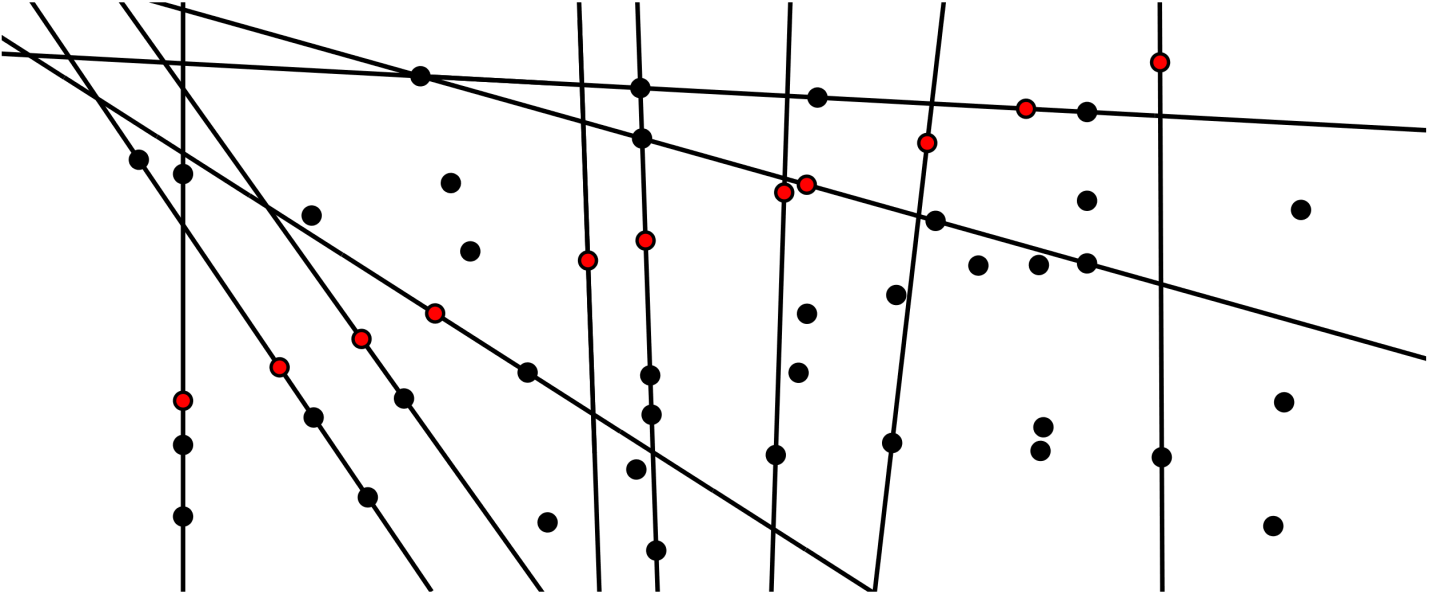
If you count the number of points on this line, you will see that there are 11. So, this is a line that covers 11 of the 48 points. That sounds pretty good! In fact, you can show that you must use this line, as one of the 8 lines. If you do not, you need to draw a separate line through all 11 points. Maybe like this:
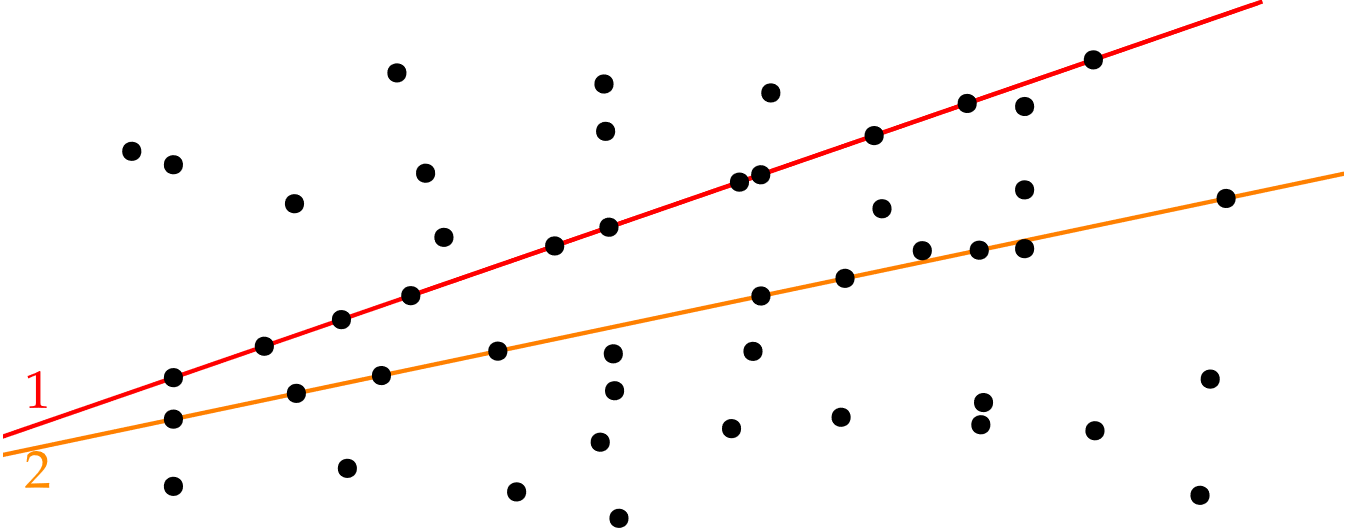
But this does not cover all points, and you are not allowed to use 11 lines, you can only use 8. So, you can draw the red line: you know for sure that it has to be used. Now, you only have to find a way to cover the 37 remaining points, with 7 straight lines. But why not use this reasoning again? Can you find a line that covers more than 8 points?
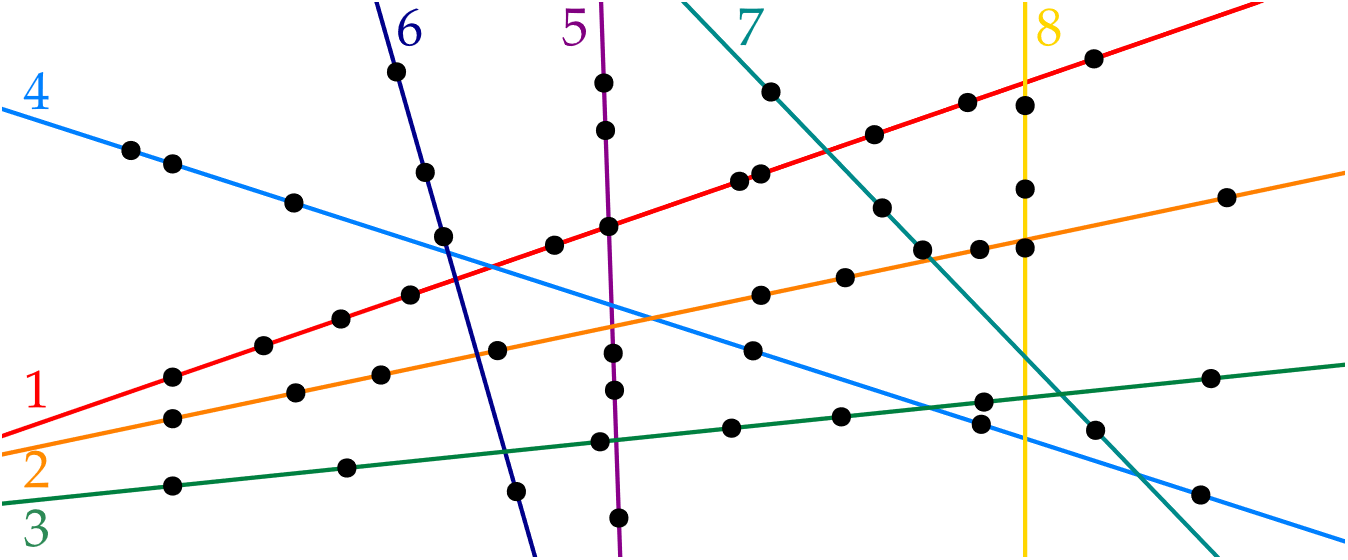
The orange line covers 8 of the remaining points, and should therefore be drawn. You can continue this reasoning and in fact, solve the entire puzzle!
The above reasoning is an example of a preprocessing rule: if you want to cover points with at most k lines, and there is one line that goes through k+1 points, you should be using that line.
It would be great if we could show that we can always apply this rule, but unfortunately, this is not the case. Yet, we can observe something else. Imagine that the rule does not apply. So, we can use at most k lines, and each line will go through at most k points. If we now have more than k*k points, there cannot be a solution at all. So, if the above rule does not work, it is guaranteed that the puzzle is small compared to the number of lines you had!
In the example above, you used a simple rule, that had a guaranteed effect. Applying the rule results in a puzzle that is small, as compared to the number of lines you are allowed to draw. This kind of preprocessing is often called kernelization.
Applications in the real world?
The puzzle above shows how kernelization works for a simple puzzle, the goal is to further improve preprocessing for real-world problems. For example, to find better delivery schedules for the delivery company, but many more problems exist, from the optimal design for a computer chip to scheduling trains.
This is challenging because real-world problems are complex. For example, the delivery company has to take into account that rush hour means that the time to get from A to B varies throughout the day, they need to take unexpected delays into account. Kernelization is a method that can improve preprocessing for such complex real-world problems.
Elisabeth already has an idea in mind: she would like to find the fastest possible route that goes to each address exactly once before finally returning to the station. This task is a well-known mathematical problem, namely the Traveling Salesman Problem (TSP)! How can she solve it?
Think of a local car dealer selling cars in your region. To make sure new cars are delivered on time a whole mechanism involving various people, factories, and transport companies, must operate in coordination. This is a highly complex process where mathematics plays an important role.
Often due to large waiting times customers abandon shops (online or physical), and owners don't realize that they have left. We call this a loss of opportunity. This is an important concept in queueing theory.
Getting to class on time isn't hard, if you leave on time and know the fastest route. But what’s the fastest route when the hallways are crowded? For their final high school project, Dylan and Tobias worked on finding the most efficient ways to navigate school during peak hours.