Whatever we want to know - from scientific discovery to home renovation - the answer is usually the same: `Look it up on the Internet'. I could not come up with any deliberate action as common as web search. Today's Google Statistics reported stunning 70546 queries per second!
In this article we will have a look at how search engines work. What happens when you type the query in the famous, almost magical, Google's white page? And what does it have to do with networks?
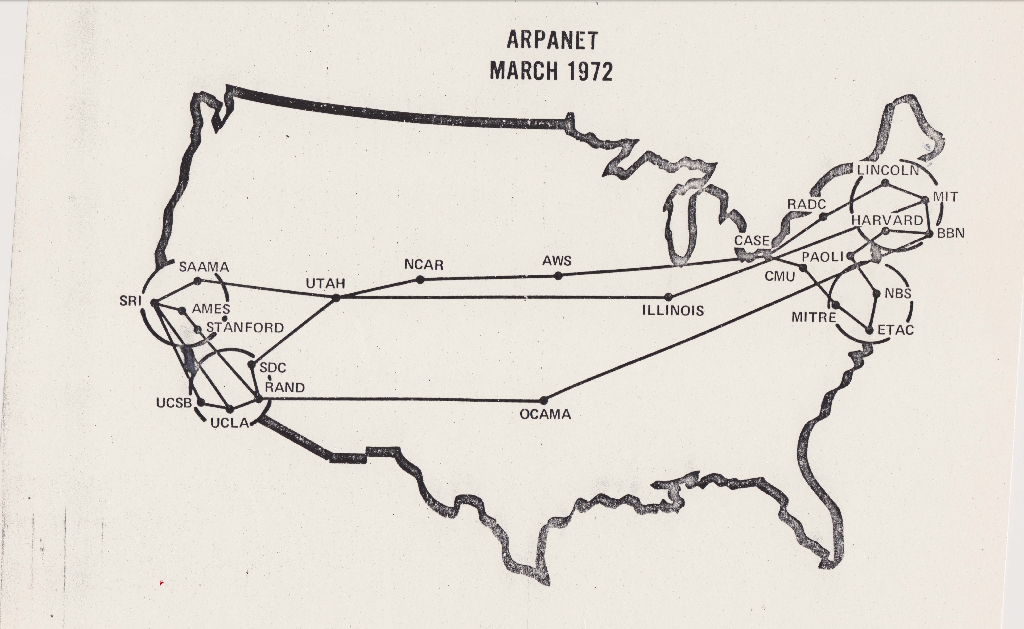
To begin with, `searching on the Internet' is technically not the right thing to say. A search engine searches in the World Wide Web. Internet and the World Wide Web are two gigantic networks, and they are not the same thing! Internet is a network of computers, or, routers, that are physically connected by wires. Internet is a technology that enables us to transfer digital information from one computer to another. This is Arpanet, the forerunner of Internet, connecting computers in several collaborating institutions in the US.
UCL and BBN [1]
Due to the work of a programmer and an artist Barret Lyon and his Opte project we can visualize how the Internet looks today
Barrett Lyon / The Opte Project. Visualization of the routing paths of the Internet.
Look at the colorful firework -- this is Internet. The colors represent different continents, and shiny white lines in the center are intercontinental fiber cables -- the backbone of the Internet. This picture is displayed in the Museum of Modern Art in New York City.
The World Wide Web, on the other hand, is not a physical, but a virtual network. It consists of web pages connected by hyperlinks that refer from one page to another. The World Wide Web was conceived in CERN, Switzerland. They still keep the world's very first website, which was actually called `World Wide Web'. Web pages are simply documents, like your ordinary Word or Excel file. Your webpage is stored on your computer. When I request it by typing its http:// address, this page is transferred from your computer to my computer, using the Internet, in fact, using one of the cables depicted in the image above!
Search engines look for relevant web pages, so technically they search on the World Wide Web, and not on the Internet. But of course, without Internet it would not be possible, because no web page could be sent to your computer from any other place in the world.
How many webpages are there? In 2013 Google was aware of 30 trillion individual web pages! Now you can imagine what an enormous task Google solves successfully, 70546 times per second!
So, how do they do it?
All modern search engines (besides Google, there is, for example, a very successful Russian Yandex and many others), are build on more or less same principles.
First, there is a program called crawler. Google's crawler is called Googlebot. The crawler physically visits all the pages, and copies their content and the links.
There are many other reasons why one may want to crawl the web, not only for web search. For example, the BUbiNG crawler by the Laboratory for Web Algorithmics (LAW) of the (DI) University of Milano (UNIMI) in Italy (IT) [2] was created for scientific purposes. Web plays a huge role in our lives, so scientists want to understand how it looks like, how it grows, how it changes, etc. The more we know, the easier we can access information, filter out spam, or spot the fake news. BUbiNG is an open access software, anyone can use it, in business and academia, and many people do!
Crawlers can be annoying. They try to copy the pages, slurping the website's capacity. Sebastiano Vigna, one of the creators of BUbiNG, says they got some angry messages from system administrators. Site owners can establish rules for the bots, for example, veto crawling of some pages or allow crawling only at night when the traffic is low.
Nevertheless, as a site owner, you do want a search engine crawler to visit your pages often enough. Because the crawler copies the content and sends it to the index, the second essential component of a search engine. In index pages are sorted, filtered and stored.
This is essentially the answer to the question: how come that the answer to a query take only a fraction of a second. Google, or any other search engine, does not search in the wild Web, it searches in its own neatly structured index.
Before a page is crawled and indexed, it does not exists for Google, and nowadays this basically equals to the page not existing at all.
The index can be compared to a constantly expanding, as complete as possible, library of the web. Yes, Google stores the entire World Wide Web on its servers!
You can imagine that this is a lot of data to store, so of course search engines need enormous storage capacity. And it's not only the entire Web that has to be stored. On top of that, add Google drives, Google maps, and other data services. Google stores the data in data centers about the world. Data centers are campuses of very robust buildings full of servers storing and processing data.
erwinboogert [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
Data centers are built in places where no earthquake or flood is expected, because such amounts of data cannot be transported anywhere, neither physically nor via Internet. One of the problems with the data centers is that they use a lot of energy. According to "Independent", in 2015 they used more energy than the entire UK!
If you think about it, it is quite astonishing how multi-faceted search industry is. When Sergey Brin and Larry Page started Google in 1998, with only several processors, busy mainly with technical side of the story, could they imagine that soon enough climate change will be one of major concerns of their company?
Besides crawling and indexing, there are other major questions related to search. To one technical problem, just type any common query and see how many hits you get. I typed `networks', and Google found about 9.940.000.000 relevant pages! How to sort them to the user so that most important hits come on top?
This was exactly the question that initially made Google the leader of the market. Their solution was to look at the network, instead of content only. They came up with PageRank algorithm, which used the links as `votes': a page is placed on top of search results when many important pages link to it. Nowadays links are still taken into account, although lately you may have noticed that personalization (where you are, your search history etc.) plays a very important role.
In the next article I will tell you more about PageRank. Now my word limit is up, time to finish my story. And once it is published, let's hope the crawler will visit soon!
If I give you a set of nodes, plus a way to find the distance between two nodes, how can you find all connections between these nodes as efficiently as possible?
During our teenage years, everything changes. It’s no surprise that our brain does too. But how do we make sense of this transformation? Is there a way to quantify it? Networks might just be the answer.
One of the main building blocks of modern AI-tools are artificial neural networks, abstract models inspired by the structure and functions of biological neural networks which enable machines to "learn". In this article, I will discuss some thoughts on this topic.
Did you know that if you divide a pack of cards into 13 piles of 4 cards, then you can always pick one card from each of the 13 piles so that there is exactly one card with each rank? There is some beautiful math behind this puzzle.